计算引擎
运用云计算技术、Docker技术、资源调度引擎技术,根据物理资源配置为客户搭建高可用计算引擎
-
环境可提供Spark/Flink伪分布式、集群模式等不同的集群环境,可提供物理机、虚拟机、容器等不同的载体系统环境。
-
能力支持主流的Nvidia/AMD图形计算卡,可提供物理接入、passthrough、vGPU等不同的计算资源分配方式。
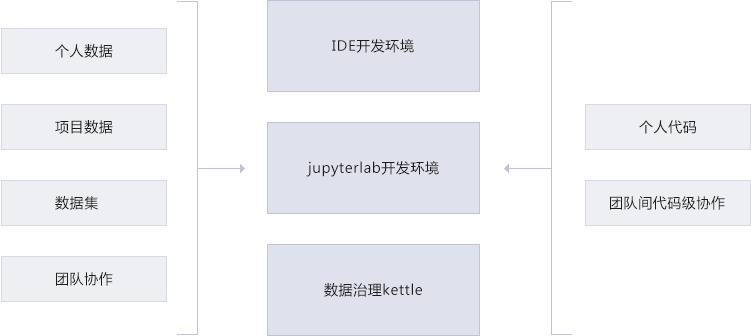
集成环境
解放科研团队搭建复杂繁琐的科研环境
-
支持工具支持语言在web端即开即用使用Eclipse、Pycharm 开发环境,使用Jupyterlab 便捷编程环境。支持Python 、Java、Scala和 R。
-
大数据平台支持能力集成大数据框架MapReduce/Spark/Flink等,弹性的算力调度,可单点或集群调度。
-
人工智能平台支持能力集成机器学习引擎TensorFow/Pytorch 等,可按需部署、动态调度。
-
支持多种数据库数据治理支持能力集成多种数据库HDFS、Hbase、Hive、Redis、Mysql等,以及CSV、Excel文件存储。集成数据治理工具kettle,数据治理库pandas、numpy等。
开发工作台
利用高性能分布式云计算资源,web端即开即用,离线训练。提高计算效率,释放个人PC
-
 Eclipse、Pycharm 开发环境
Eclipse、Pycharm 开发环境 -
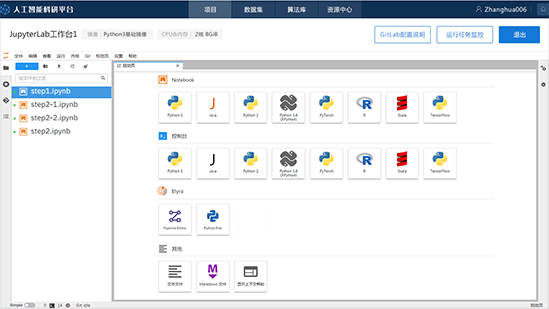 JupyterLab 便捷编程环境(支持Python 、Java、Scala和 R)
JupyterLab 便捷编程环境(支持Python 、Java、Scala和 R)